Holly Bella Wallace

Monday, January 7, 2013
HOLLY BELLA WALLACE
Born: circa April 2003
Became beloved: circa Saturday, December 20, 2003
Died: Thursday, October 24, 2013, ~5:15 PM CDT
I will always love you, sweet Holly. You beautiful, sweet baby girl.

Saturday, March 29, 2008
Adventures in the Evil Land of iTunes
I was in the U.S. iTunes store in my Windows VM, fruitlessly searching for the album for Ludovico Einaudi’s 2007 iTunes Festival performance (I was using iTunes only because it’s from the iTunes Festival; I avoid anything made by Apple to the fullest extent possible), when I found this:

I was wondering why it would show up in the search results for Einaudi, so I clicked on it only to find this:
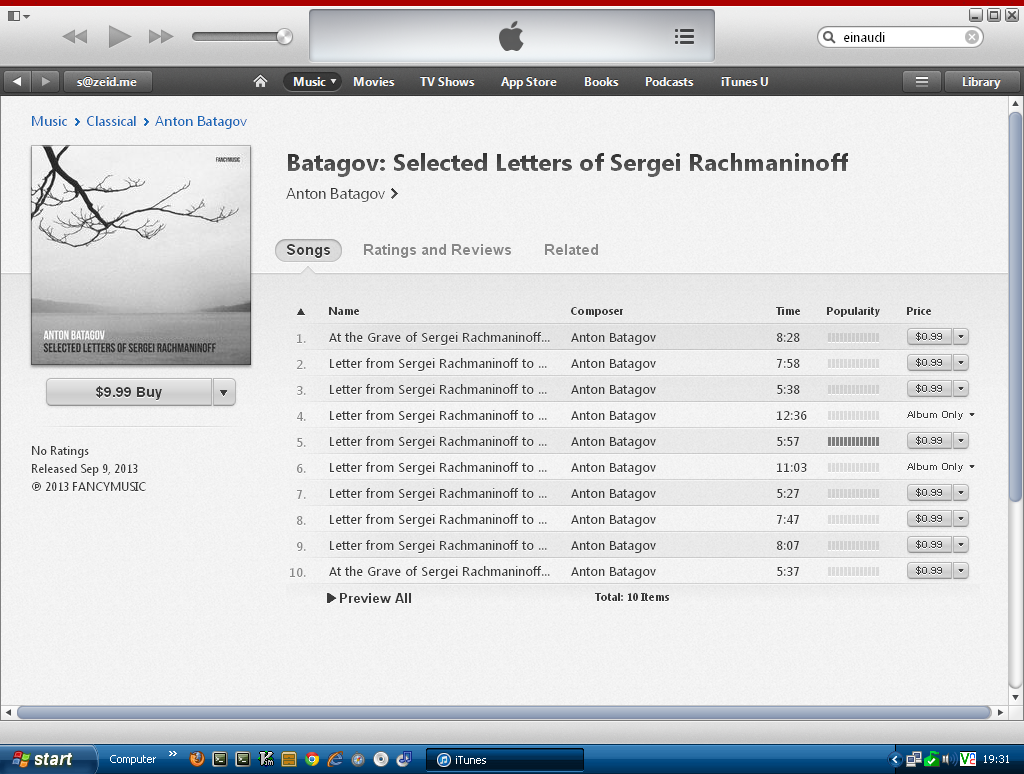
Of course, it doesn’t show the full track names in a tooltip, so I go to the Web page for it. Of course, it doesn’t show tooltips either, so I fiddle around with the CSS a bit to widen the column and see this:
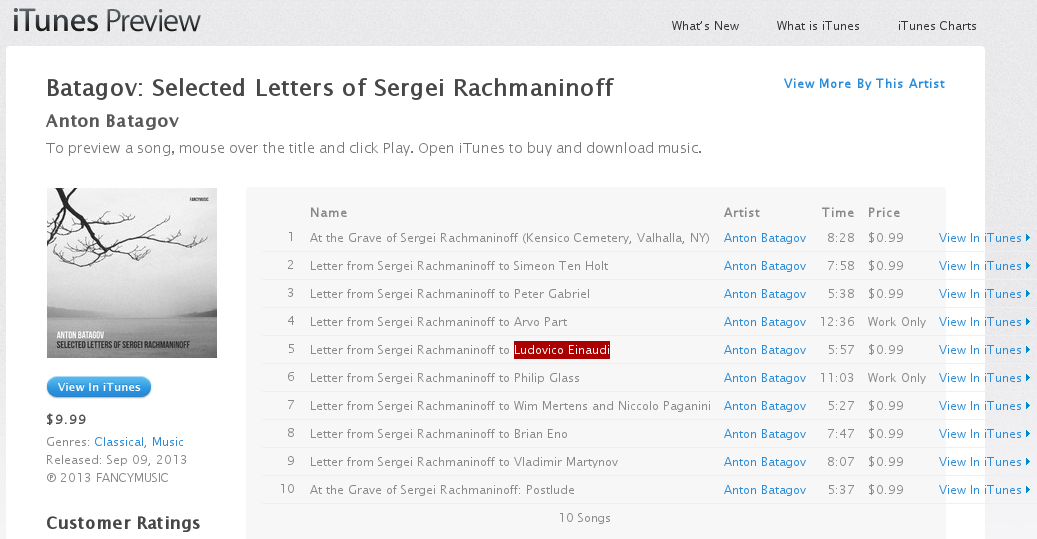
I looked back at the page in the iTunes app and noticed that track five is the only popular song on the album. After seeing the full name of the track, it’s little wonder why! XD
P.S. It’s a beautiful album; you should listen to it! (Through a place other than iTunes, of course!) You should also read Anton Batagov’s write-up about his inspiration for the album. (Also, track 4 should say “Arvo Pärt”, not “Arvo Part”.)
P.P.S. Why the fuck do I have to set up a proxy in Ireland hunt down
an obscure music store in New Zealand in order to buy Ludovico’s 2007 iTunes
Festival album‽‽‽
P.P.P.S. Einaudi’s 2013 iTunes Festival concert is fucking epic. If only it were lawfully available for download, and outside of iTunes….
Update (2013-10-02): I was able to get Ludovico’s 2007 iTunes Festival, finally. It only took about six hours of Googling in order to find a music store in New Zealand that didn’t check my billing address to see if I’m in the right country, and then I had to wait about 12 hours for them to manually release the order, and even then their download page was buggy. I really wish the record labels would get their shit together. I should probably do a more detailed blog post about all the troubles I’ve had getting Ludovico’s full discography and how his record labels (yes, he’s actually signed to more than one label) are fucked up.
Fun with Google Reader JSON files
So if you haven’t heard already, Google Reader is shutting down on July 1, 2013. However, until then, you can take your data out using Google Takeout and you’ll have all your subscriptions and starred, liked, and shared articles. The problem is that the article lists are JSON files with a custom schema that there aren’t (as far as I know) any user-friendly parsers for, so I made one.
Stella runs entirely in your modern, standards-compliant, HTML5 FileReader API-supporting Web browser (you are using one, right?) and lets you view any Google Reader article list in JSON format, including your starred, liked, shared, and notes lists, as well as any subscriptions you’ve exported in JSON format (more on that in a minute). All you have to do is click “Select JSON file”, select your file, and start reading!
Stella also lets you save a static HTML page which you can view offline. The page
will also contain an exact copy of the JSON file you selected (with HTML special
characters escaped). (Clicking “Static page” will only give you a Save As screen
in a few browsers, notably Chrome 14+ and Firefox 20+. Other browsers will show
the static page in a new tab, and you’ll need to right-click the link or page
and choose “Save Page/Link As” to save it. Also, saving static pages will only
work at all in browsers that support the Blob API (look under “Blob()
constructor”).)
It’s worth noting that Google Reader JSON files do contain the full contents of each article, and Stella does let you view those.
The source code to Stella is available on GitLab and is released
under the X11 License. If you modify the JavaScript or CSS files, run make to
regenerate the stella.combined.{js,css} files; otherwise, you won’t see your
changes.
Exporting feeds (or folders) as JSON files
(Permalink to this section) Now, I mentioned earlier that you can export your subscriptions as JSON files as well. This also exports the article contents. This is insanely useful as Google Reader keeps an archive of EVERY ARTICLE EVER POSTED IN THE FEED, even if they were posted after you subscribed to the feed (but after at least one person has done so), even for feeds that have since been removed by their publishers. This is one thing that I’ve really loved about Google Reader, and I’m thrilled to learn that you can export every article ever posted in a feed that has been subscribed to in Google Reader. Oh, and it works for folders, too!
To export a feed or folder as a Google Reader JSON file:
- Open the subscription in Google Reader.
-
In the URL in your browser’s location bar, replace “
/view/#stream/” with “/api/0/stream/contents/”. So, for example,https://www.google.com/reader/view/#stream/feed%2Fhttp%3A%2F%2Fxkcd.com%2Frss.xmlwould become
https://www.google.com/reader/api/0/stream/contents/feed%2Fhttp%3A%2F%2Fxkcd.com%2Frss.xml - Add
?n=999999999to the end of the new URL. If you skip this step, it would only give you the first 20 or so articles in the feed, although it appears that there’s still a limit of one thousand articles. If your feed has more than 999,999,999 articles (which would be insanely unlikely), you would want to increase that number. - Hit
Alt+Enterto open the JSON file in a new tab. From here, you can right-click and choose “Save Page As” to save it, but be sure to give it a filename that ends in “.json”. - (Optional) Open the file in Stella!
I cannot stress enough that if you want to do this, and/or export your starred, saved, shared, and notes lists, you MUST do it before July 1, 2013, as that is the date that Google Reader shuts down.
New Site
So, about a month ago, I redesigned my site and moved it to
Jekyll. The impetus for this was
that after a WordPress update, my site basically broke: top-level pages
(e.g. me.srwz.us/about would work, but not, say, me.srwz.us/iphone/appbackup)
and I couldn’t find the cause. Also, WordPress is slow as fuck on my
server, and I was tired of having to use a GUI (and a slow one at that)
to update my site. I’m a command-line guy, so why not edit my site on
the command line?
So I spent about a couple of weeks, starting on around September 26, doing pretty much nothing but going to class and working on the new site, finally getting it up on October 5, I think. Most of that time was spent working on the site navigation plugin, closely followed by the Liquid templates, since I was wanting to replicate most of the functionality from my old WordPress site, which proved to take a rather large amount of coding. I also added some new functionality, like subpage listings and tables of contents in the sidebar on pages (see Projects and AppBackup for examples). Currently missing are blog archives and comments (I’m wanting to use jskomment or make my own comment system using TrailBehind’s Comment Widget and a minimalistic PHP backend). I really don’t want to use a third-party hosted comment system like Disqus because I don’t want the comments to be dependent on a third party which could go out of business or otherwise lose or remove them.
This was my first real experience with Ruby, which is a rather
interesting language, and with responsive design (try visiting my site
on your smartphone, or just resize the window (or press Ctrl-Shift-M
if you’re running Firefox 16 or later to open Responsive Design View)
to see the mobile version), so all of this was a really good learning
exercise as well.
As for the design itself, well, I didn’t really have a specific plan for
it, but I kind of just had a rough idea in my head of what I wanted and
just made it as I went along. I ended up rewriting the stylesheets using
Stylus, which I chose mainly
because I liked the syntax better than that of LESS and SASS (and
transparent mixins
in particular). This was actually my first experience using a CSS
preprocessor, and I must say it’s much more pleasant than writing plain
CSS, although I was surprised at the huge difference in the sizes of the
Stylus sheets (653 lines total, including blanks) and the compiled CSS
files (1,619 lines total). (The largest stylesheet by far is screen,
with the Stylus version
being 258 lines long and the compiled version
being 1,082 lines long. This may be due in part to some inefficient loops
and stuff. I should probably turn on GZIP compression in lighttpd to make
up for it.)
Oh, and speaking of lighttpd, I did move my site over to lighttpd. I was using Cherokee since mid- or late 2010 because I got fed up with Apache’s config format and out of laziness, but of course I now find configuring lighttpd in Vim easier than having to use a buggy Web interface (having the page jump up to the top every time I click out of a text box is really annoying). I did look at nginx a lot, but the ability to properly add custom CSS to directory listings (as opposed to using a sub_filter hack) sold me on lighttpd (silly reason, I know). I kind of feel like I might like nginx’s config format better, though, but for now I’ve already put a lot of work into my lighttpd configuration. (It’s 333 lines long right now, including blanks. I have a lot of old stuff as well as some other things in there.)
Also, the day after I launched my new site, my awesome Web host
upgraded me to a VPS with double the RAM (512 MB)
and four times the disk space (24 GB) compared to what I had before. They
had promised this upgrade last year to everyone (including me) who moved
over to their new IP address block within the first 30 days, but you had
to ask for it, and I never did, but then my dom0, cerberus, gave out
,
and they decided to just upgrade everyone on cerberus who was eligible.
So when I logged into my server on the 6th, I noticed that it had rebooted
recently, but then I noticed in my Byobu status line that my RAM usage was
at about 495 MB, then checked my disk size, and I was really happy when I
realized that I had finally gotten the upgrade.
And I’m also happy with my new domain name, zeid.me, and with having
s.zeid.me as my new home page URL.
So I’m pretty happy with my new site, and in a couple of days, I’ll take the You’ve Been Owned campaign off so you can enjoy the design a bit more (if you like it, which I hope you do). I do want to start blogging more, and hopefully with my new setup, I’ll feel like doing so more often.
"Address already in use" error when OpenVPN is NOT running
So for the past week or so I’ve been trying to set up a dual-stack-payload OpenVPN server. I was playing around with some IPv6 route settings earlier when it started doing this:
$ sudo openvpn /etc/openvpn/server.conf
Wed Aug 31 02:41:06 2011 Herp derp, herpity derp derp...
Wed Aug 31 02:41:06 2011 TCP/UDP: Socket bind failed on local
address [AF_INET]64.71.167.212:1194: Address already in use
Wed Aug 31 02:41:06 2011 Exiting due to fatal error
$ echo "OH FUCK WHY WONT IT WORK!!!!1!1one!!1!"
OH FUCK WHY WONT IT WORK!!!!1!1one!!1!
$ cat /etc/openvpn/up.sh
#!/bin/sh
sysctl -w net.ipv4.ip_forward=1
sysctl -w net.ipv6.conf.all.forwarding=1
ip link set $dev up promisc on mtu $tun_mtu
brctl addif br0 $dev
iptables -t nat -A POSTROUTING -s 10.4.4.0/24 -o eth0 -j MASQUERADE
service radvd restart
true
$ sudo lsof -i ":openvpn"
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
radvd 2486 root 6u IPv4 12816 0t0 TCP srwz.us:openvpn (LISTEN)
radvd 2487 radvd 6u IPv4 12816 0t0 TCP srwz.us:openvpn (LISTEN)
WHAT??? radvd is listening on OpenVPN’s port?
Some background: I was restarting radvd in the up script because it’s set to advertise on tap0, but tap0 doesn’t exist when the system boots, so instead of messing with the init scripts, I decided to just restart radvd in the up script. However, since the up script is executed as a subprocess of OpenVPN, it apparently inherits OpenVPN’s sockets, and radvd in turn inherits the shell script’s sockets, causing problems when you restart OpenVPN (even with SIGHUP, I would assume). *
Now I do have IgnoreIfMissing on; in my radvd.conf file (it’s not the default
yet in the radvd 1.7 that ships with natty), but I didn’t realize that starting
radvd succeeded when tap0 didn’t exist, which is why I was doing it in the up
file. radvd rereads its config file on SIGHUP, so to fix the issue, I simply
changed this line in the up script:
service radvd restart
to:
kill -HUP `cat /var/run/radvd/radvd.pid`
and restarting OpenVPN worked again.
Time to go to bed now. I hope this helps someone.
* Disclaimer: I don’t have 200 years of UNIX experience like some people do, so I may be a little bit wrong about this. But I’m probably right. :)
OpenVPN 2.2.1 + IPv6 Payload Patch for CyanogenMod 7.1 RC1
I’ve ported Gert Döring’s IPv6 payload patch for OpenVPN to CyanogenMod. I want to try to get it into the CM source tree someday, but here are the goods in the meantime.
- Binary built for the original CDMA Droid (sholes) on 2011-08-26
- Install to your phone as
/system/xbin/openvpn. - Change owner and group to
rootand permissions to0755. - May work on other ARM phones running CM, although I haven’t tested it on any of them except my Droid 1.
- May not work on other Android ROMs because the paths to ifconfig/route/ip are configured at compile time.
- SHA-256 sum
- Install to your phone as
- CyanogenMod patch (valid as of 2011-08-26)
cd /path/to/cm/source/external/openvpnzcat /path/to/openvpn-2.2.1-ipv6-cm7.1rc1-20110826-1.patch.gz | patch -p1- SHA-256 sum
- GitHub fork of CyanogenMod/android_external_openvpn
- I had to rebase Gert’s patch for OpenVPN 2.2.1. Here it is.
Enjoy! I will not provide support for any of this, so use it at your own risk and don’t come crying to me if it hacks your Facebook and changes your relationship status or something. I really can’t help you with that. :P
Google+ Tango Icon
I’ve made a Tango-style Google+ icon.
For more information and SVG downloads, see my Tango Icons page.
AppBackup 2.0.2 released!
AppBackup 2.0.2 is out and fixes the following issues:
- Fixed a bug with translations where if something wasn’t translated then nothing would appear in the UI (expected behavior is that the English text would appear instead).
- AppBackup no longer crashes if backuptimes.plist is corrupted or malformed.
Also, the Czech, Japanese, and Korean translations have been updated. The new version should be on Cydia soon.
AppBackup 2.0.1 released
AppBackup 2.0.1 has been released and should be on Cydia soon. It fixes the bug where the app was hanging on the Please Wait screen.
Changes:
- Fixed the problem where AppBackup was hanging on the Please Wait screen for many people.
- Fixed a cosmetic bug with the Please Wait screen.
- Updated Spanish translation.
- ini-to-strings.py now sorts the list of language files before converting them.
AppBackup 2.0 is finally finished!
After a long wait, the new version of AppBackup AppBackup 2.0, is finished and has been submitted to BigBoss. It will show up on Cydia within a day. Here is what has changed in 2.0:
- AppBackup now works on iOS versions 4.3.x and later (and it still works with iOS 3; untested on iOS 2).
- Added a confirmation screen for all actions.
- Redesigned About screen.
- AppBackup has been split into two parts:
- The GUI, written in Objective-C this time.
- A command-line interface in the form of a Python package. (Just type
appbackupat the terminal to use it.) - As a result, the code has been completely rewritten and is much cleaner and object-oriented.
- The FixPermissions utility can now be used by typing appbackup-fix-permissions at the terminal. It is still run automatically in the GUI mode only.
- Updated translations and added new translations for the following languages:
- Czech - Jan Kozánek
- Chinese - goodlook8666
- Greek - Spiros Chistoforos-Libanis
- Japanese - Osamu
- Korean - Joon Ki Hong
- Norwegian - Jan Gerhard Schøpp
- Changed translations format in the source tree.
- Translations are now managed on Transifex (https://www.transifex.net/) and converted to Apple’s Localizable.strings format at build time.
I would like to thank everyone who has been patient while I was working on fixing AppBackup, and I am very sorry it took so long.
AppBackup 1.0.14 is released
I have released AppBackup 1.0.14. This is a SECURITY UPDATE. You should update AS SOON AS POSSIBLE in order to keep your device secure.
AppBackup still does not work on iOS 4.3.x; however you should still update for security reasons. I am in the process of rewriting AppBackup so that it will work on iOS 4.3.x, and I am very sorry for the long wait.
Download or wait for it to show up on BigBoss.
Eric Whitacre's Virtual Choir 2.0 Premiere is tomorrow!
Eric Whitacre’s Virtual Choir 2.0
(which I happen to be in) premieres tomorrow at 5 PM central time. You can watch
the premiere event live at WQXR.org or wait for
it the Virtual Choir video to hit
YouTube.
Update (2011-04-08): The YouTube video is up! https://www.youtube.com/watch?v=6WhWDCw3Mng
Update 2 (2011-04-11): You can watch an archived version of the premiere at livestream.com.
Forcing DD-WRT to use the desired DNS server
I should NOT have to add
server=74.82.42.42
no-resolv
to my DNSMasq config in DD-WRT in order for it to use the DNS server I want it to and NOT my ISP’s DNS servers with their lack of IPv6 Google and spamming queries for non-existent domains. And yes, I did set the DNS server on the main setup page.
AppBackup 1.0.13 released
I’ve released version 1.0.13 of AppBackup, which brings the following changes with it:
- Added the ability to ignore and un-ignore apps in the backup list and when using the All button.
- Fixed a crash caused by an error in the Dutch translation. (Tim van Neerbos was consulted about the problem string. This bug only affected users who have their language set to Dutch.)
- The unique bundle ID of each app is now displayed under its name in the backup/restore prompt.
Download or wait for it to show up on BigBoss.
Welcome to my new site!
Welcome to my new site and blog! Don’t expect this to have very many interesting posts; I expect to just post AppBackup updates and random programming stuff here.